We can also look at the 95% confidence interval – we are 95% “confident” the effect of age on the number of children a person has is between…
Statistical significance
The last (and most controversial) way to quantify uncertainty is statistical significance
We want to make a binary decision: are we confident enough in this estimate to say that it is significant?
Or are we too uncertain, given sampling variability?
Is the result significant, or not significant?
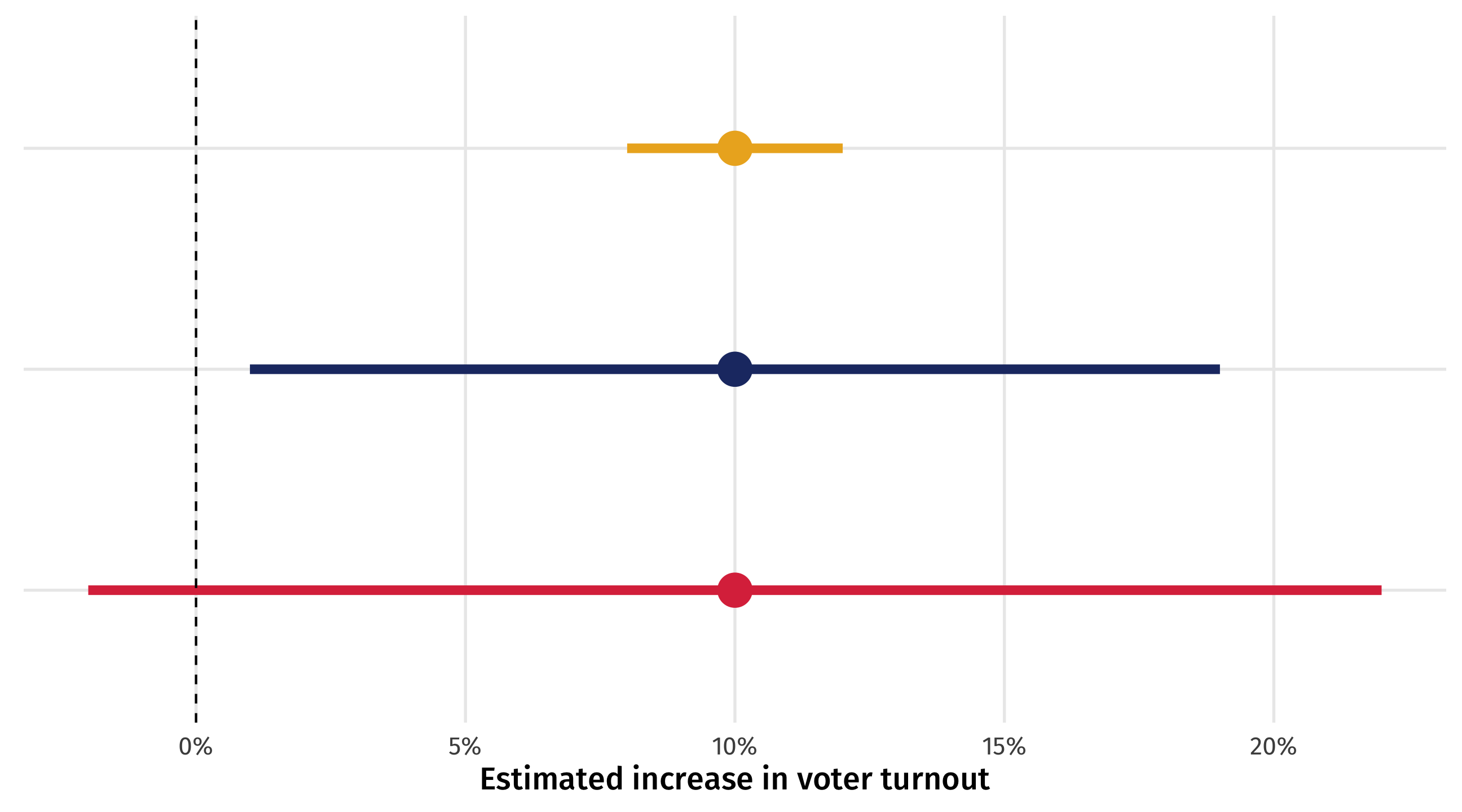
Can you persuade voters?
Imagine we run an experiment on TV ads, estimate the effect of the treatment on voter turnout, and the 95% confidence interval for that effect
The experiment went well so we are confident in causal sense, but there is still uncertainty from sampling
Three scenarios
Three scenarios for the results: same effect size, different 95% confidence intervals
How much should we worry?
Small range: great! Effect is precise; ads are worth it!
Big range: OK-ish! Effect could be tiny, or huge; are the ads worth it? At least we know they help (positive)
Crosses zero: awful! Ads could work (+), they could do nothing (0), or they could be counterproductive (-)
Crossing zero: the worst scenario
When the 95% CI crosses zero we are so uncertain we are unsure whether effect is positive, zero, or negative
Researchers worry so much about this that it is conventional to report whether the 95% CI of an effect estimate crosses zero
When a 95% CI for an estimate doesn’t cross zero, we say that the estimate is statistically significant
If the 95% CI crosses zero, the estimate is not statistically significant
Statistical significance
Statistical significance is a blunt instrument: our first two studies are quite different, but we would say they are both statistically significant
Hypothesis testing
Statistical significance is at the center of hypothesis testing
Researcher wants to decide between two possibilities:
null hypothesis (\(H_0\)): the ad has no effect on turnout
alternative hypothesis (\(H_a\)): the ad has some effect on turnout
A statistically significant estimate rejects the null
Remember this is all about sampling uncertainty, not causality!
Arbitrary?
You could have an estimate with a 95% CI that barely escapes crossing zero, and call that statistically significant
And another estimate with a 95% CI that barely crosses zero, and call that not statistically significant
That’s pretty arbitrary!
And it all hinges on the size of the confidence interval
if we made a 98% CI, or a 95.1% CI, we might conclude different things are and aren’t significant
The 95% CI is a convention; where does it come from?
The arbitrary nature of “significance testing”
Fisher (1925), who came up with it, says:
It is convenient to take this point [95% CI] as a limit in judging whether [an effect] is to be considered significant or not. (Fisher 1925)
But that other options are plausible:
If one in twenty [95% CI] does not seem high enough odds, we may, if we prefer it, draw the line at one in fifty [98% CI]… or one in a hundred [99% CI]…Personally, the writer prefers…[95% CI] (Fisher 1926)
The significance testing controversy
So arbitrary! Why do it?
Sometimes we have to make the call:
when is a baby’s temperature so high that you should give them medicine?
100.4 is a useful (arbitrary) threshold for action
This is a huge topic of debate in social science, other proposals we can’t cover:
redefining how we think about probability
focusing on estimate sizes
focusing on likely range of estimates
Statistical significance in R
The stars (*) in regression output tell you whether an estimate’s confidence interval crosses zero and at what level of confidence
This is done with the p-value (which we don’t cover), the mirror image of the confidence interval
Number of kids
(Intercept)
0.153
(0.086)
age
0.035 ***
(0.002)
nobs
2849
*** p < 0.001; ** p < 0.01; * p < 0.05.
Reading the stars
(*) p < .05 = the 95% confidence interval does not cross zero
(**) p < .01 = the 99% confidence interval does not cross zero
(***) p < .001 = the 99.9% confidence interval does not cross zero