Uncertainty I
POL51
September 30, 2024
Uncertainty in the wild
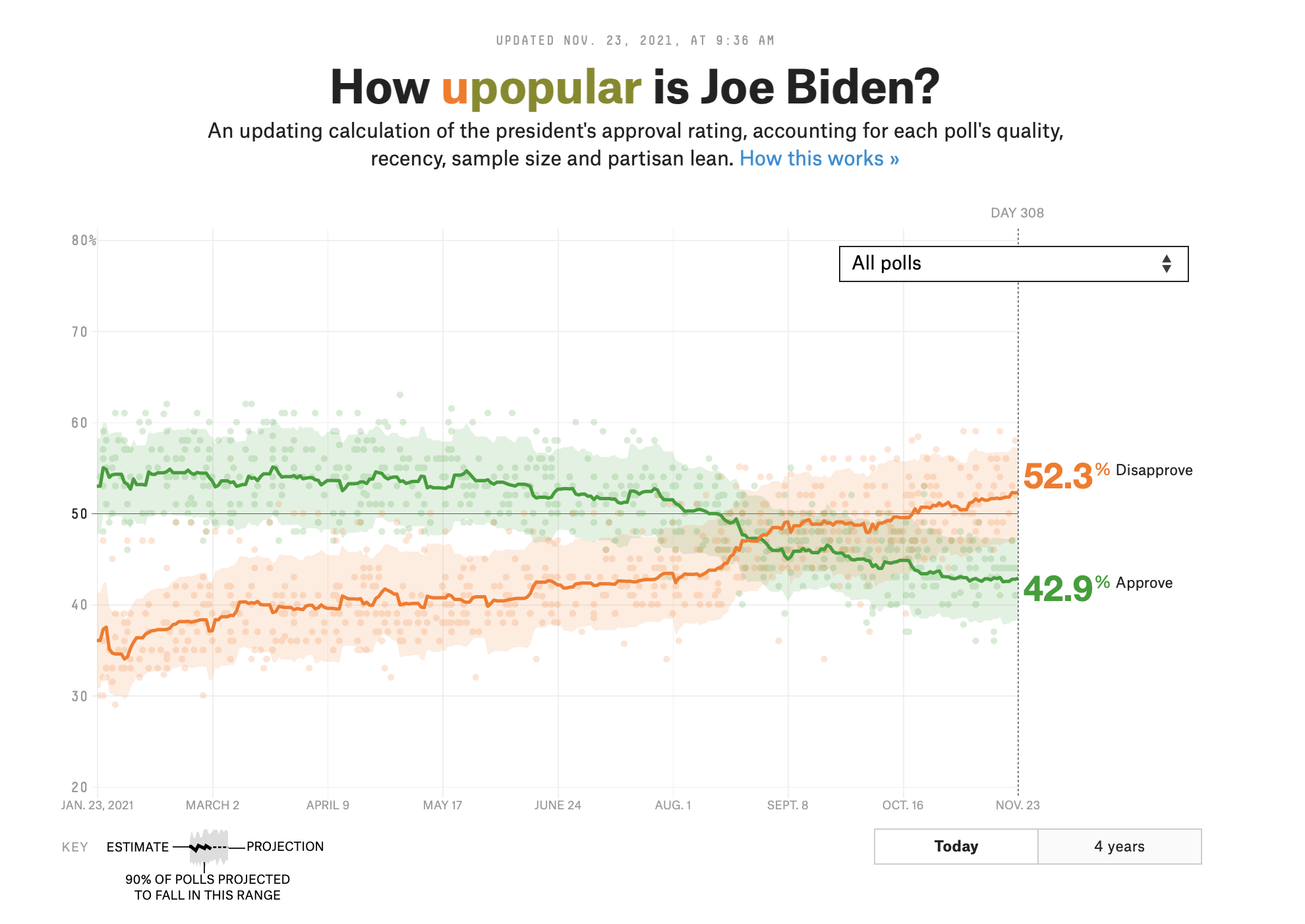
Uncertainty in the wild
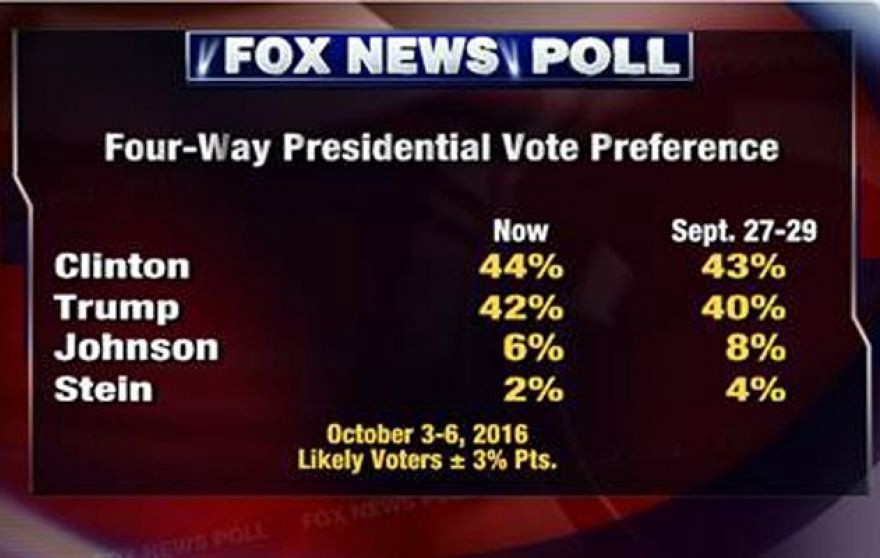
Uncertainty in the wild
The “bounds” in geom_smooth tells us something about how confident we should be in the line:
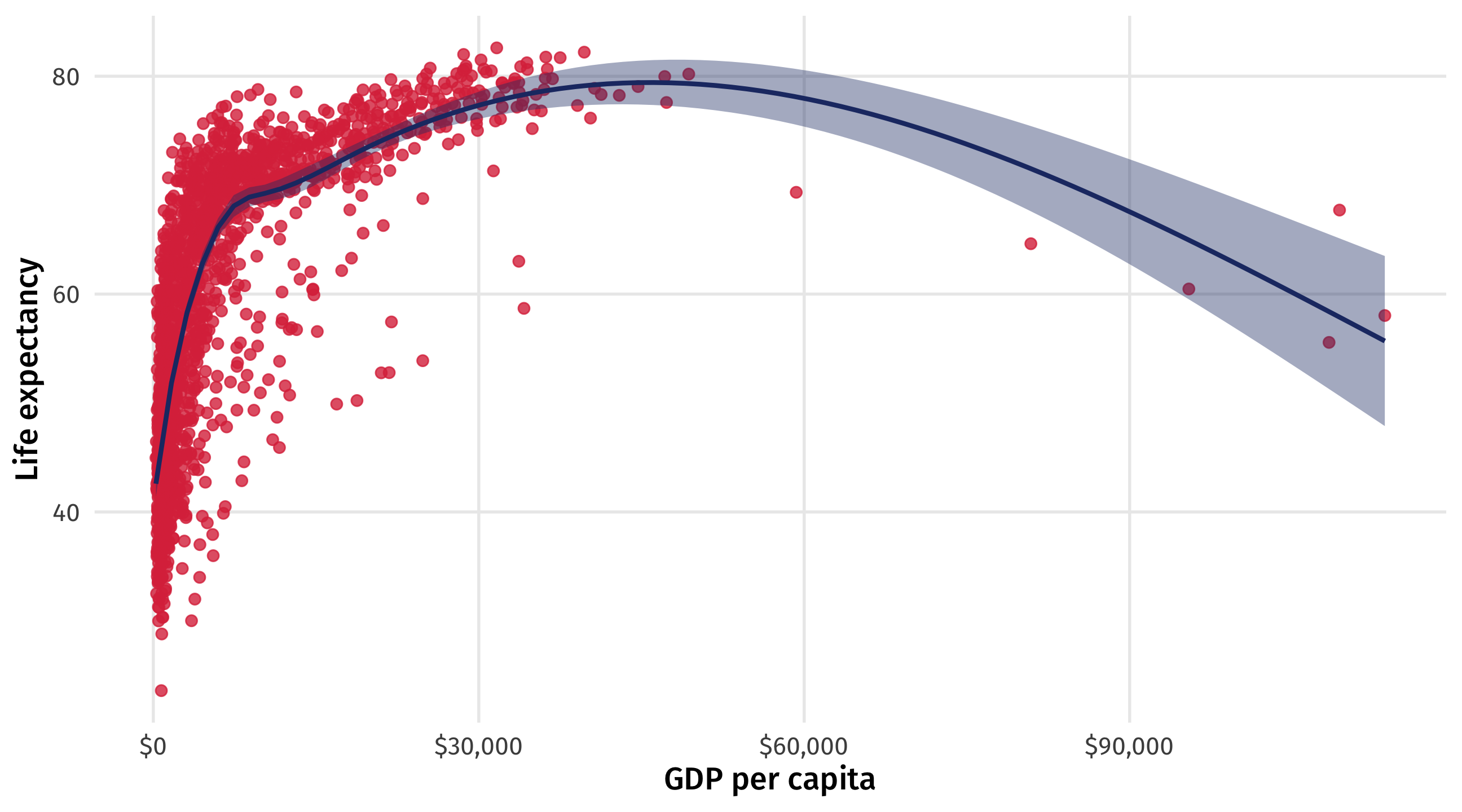
The trouble with samples
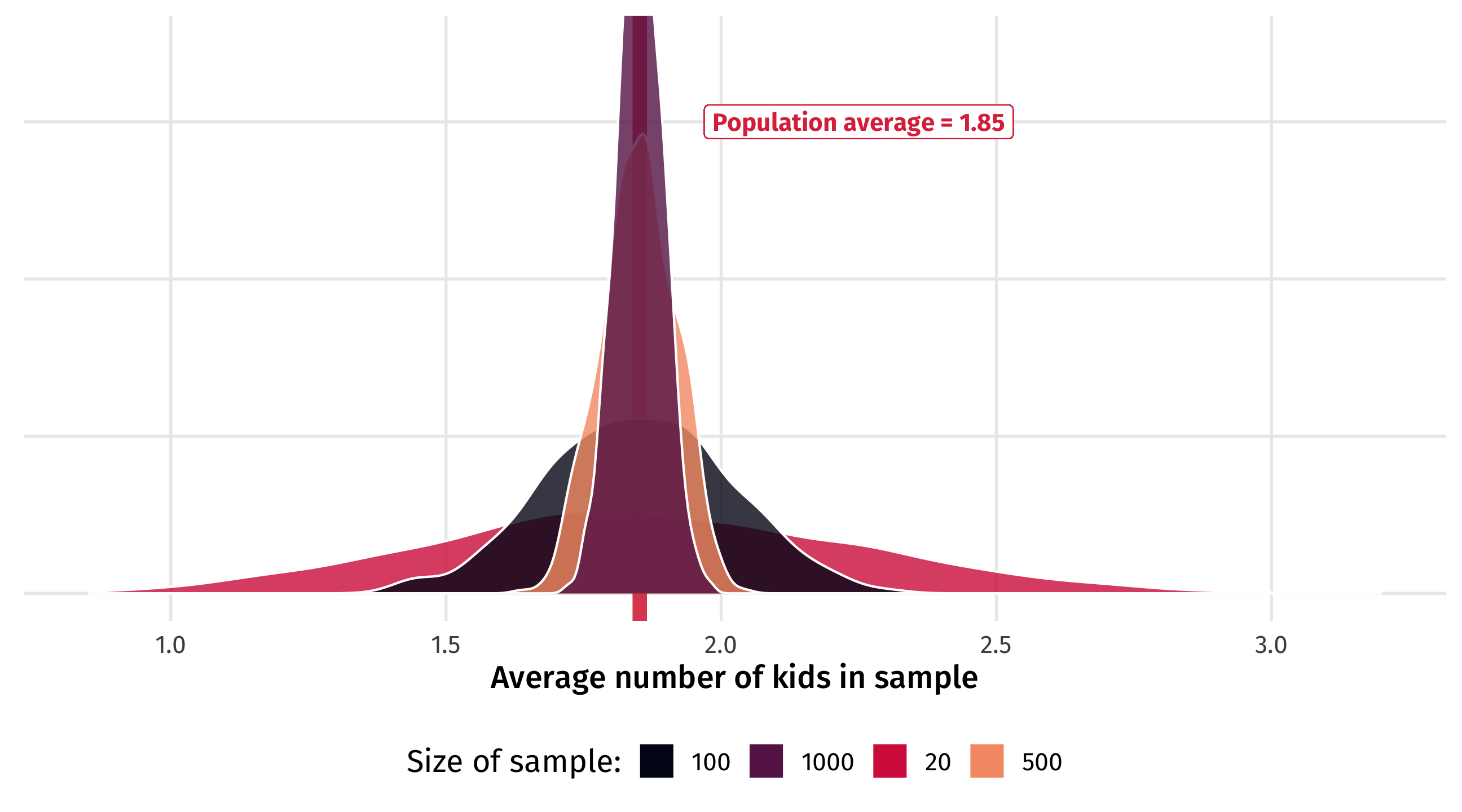
Across 1,000 samples of 10 people each, the estimated average number of kids can vary between 0.4 and 4!! Remember, the true average is 1.85

Wrong effect estimates
Many of the effects we estimate below are even negative! This is the opposite of the population parameter (0.087)

The solution
So how do we know if our sample estimate is close to the population parameter?
Turns out that if a sample is random, representative, and large…
…then the LAW OF LARGE NUMBERS tells us that…
the sample estimate will be pretty close to the population parameter

Law of large numbers
With a small sample, estimates can vary a lot:

Law of large numbers
As the sample size (N) increases, estimates begin to converge:

Law of large numbers
They become more concentrated around the population average…

Law of large numbers
And eventually it becomes very unlikely the sample estimate is way off
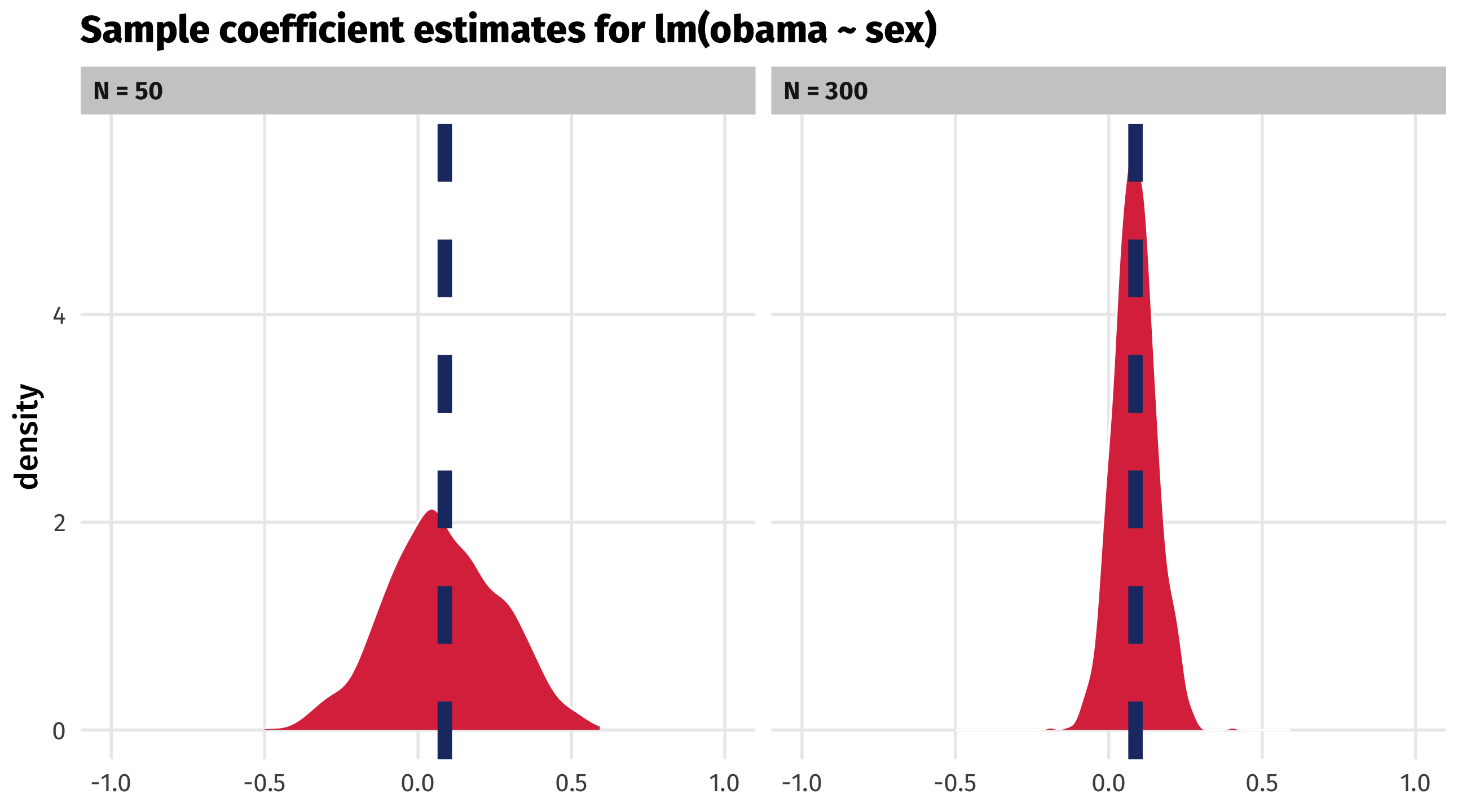
This works for regression estimates, too
Regression estimates also become more precise as sample size increases:
Good and bad samples
There are good and bad samples in the world
Good sample representative of the population and unbiased
Bad sample the opposite of a good sample
What does this mean?

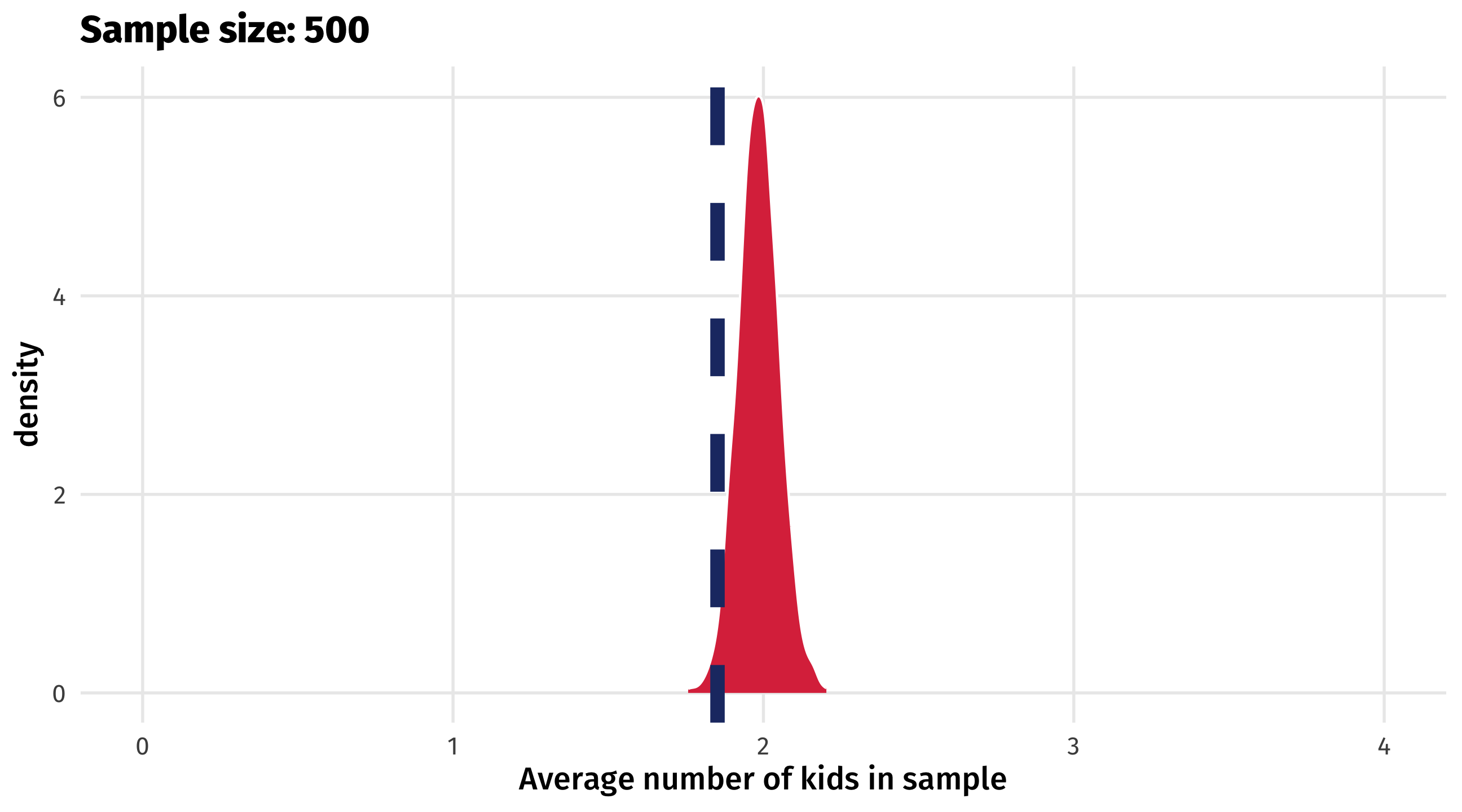
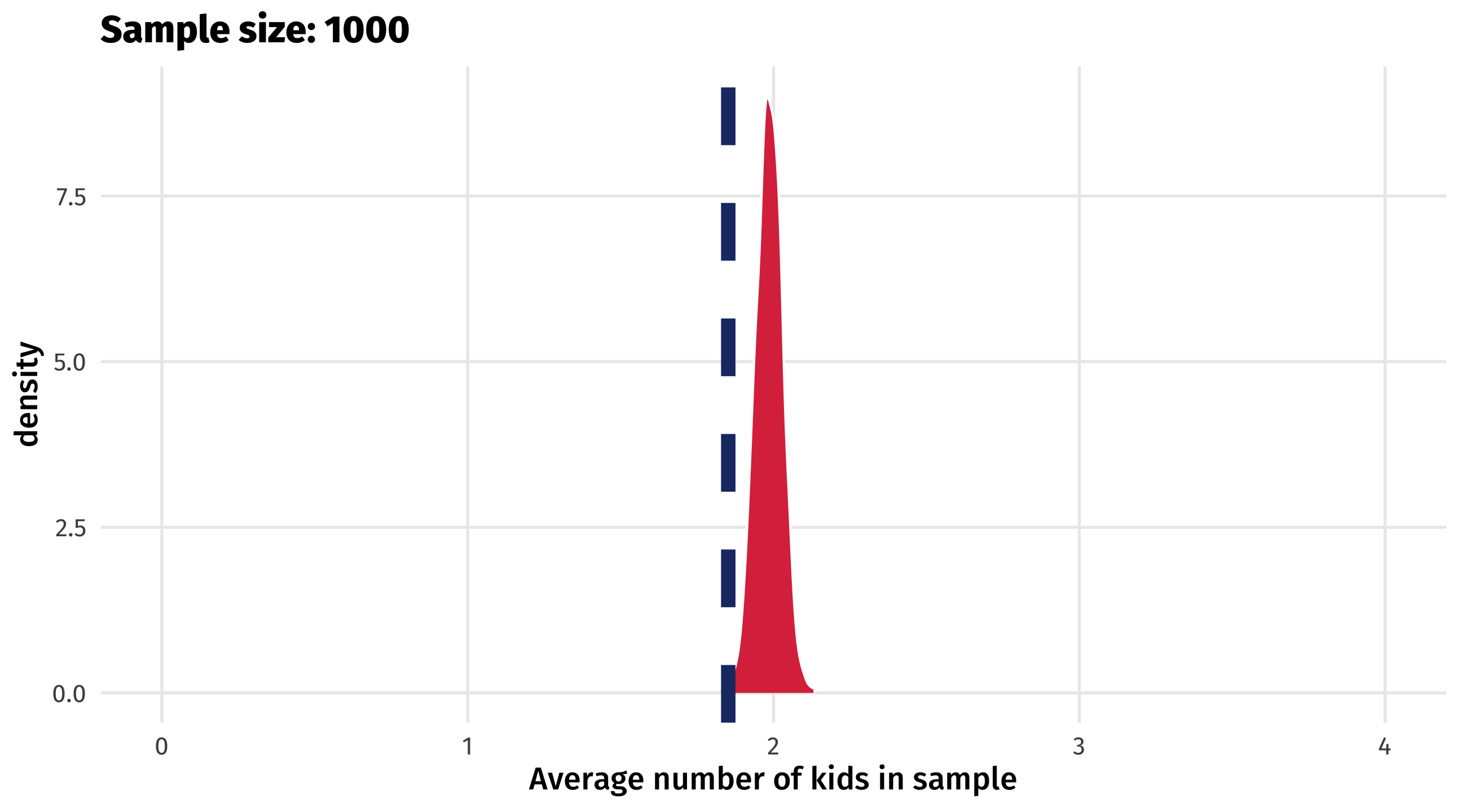
When sampling goes wrong

When sampling goes wrong
As sample size increases, variability of estimates will still decrease
When sampling goes wrong
But estimates will be biased, regardless of sample size
A big problem!
Key takeaways
We worry that each sample will give us a different answer, and some answers will be very wrong
The tendency for sample estimates to approach the population parameter as sample size increases (the law of large numbers) saves us
But it all depends on whether we have a random, representative (good) sample; no amount of data in the world will correct for sampling bias
