Prediction
POL51
September 30, 2024
Making predictions
The basics of prediction are pretty straightforward:
- Take/collect existing data ✅
- Fit a model to it ✅
- Design a scenario you want a prediction for ☑️
- Use the model to generate an estimate for that scenario ☑️

What’s the scenario?
- A scenario is a hypothetical observation (real, or imagined) that we want a prediction for
- You define a scenario by picking values for explanatory variables
- Example: what is the predicted fuel efficiency for a car that weighs 3 tons?
- Example: what vote share should we expect for Democrats in a county with a median income of 45k, a large urban center, and where the percent of non-white residents is 50%?

Trivial
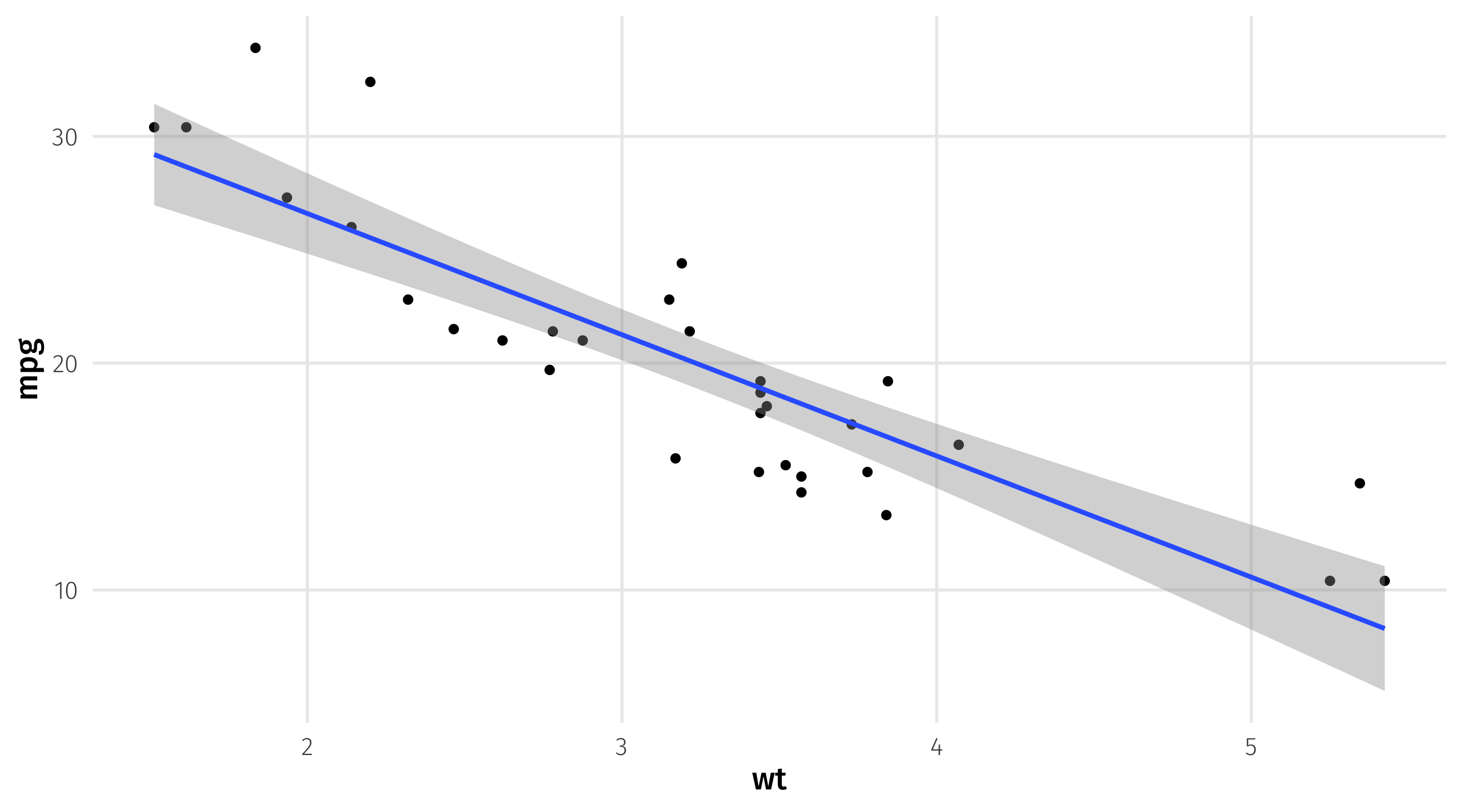
Do we really need a model to predict MPG when weight = 3.25? Probably not
Multiple regression
Just as when we had one variable, our OLS model is trying to find the values of \(\beta\) that “best” fits the data
OLS estimator = \(\sum{(Y_i - \hat{Y_i})^2}\)
Where \(\widehat{Y} = \beta_0 + \beta_1 x_1 + . . . \beta_4 x_4\)
Now searching for \(\beta_0 ... \beta_4\) to minimize loss function

lm() hard at work
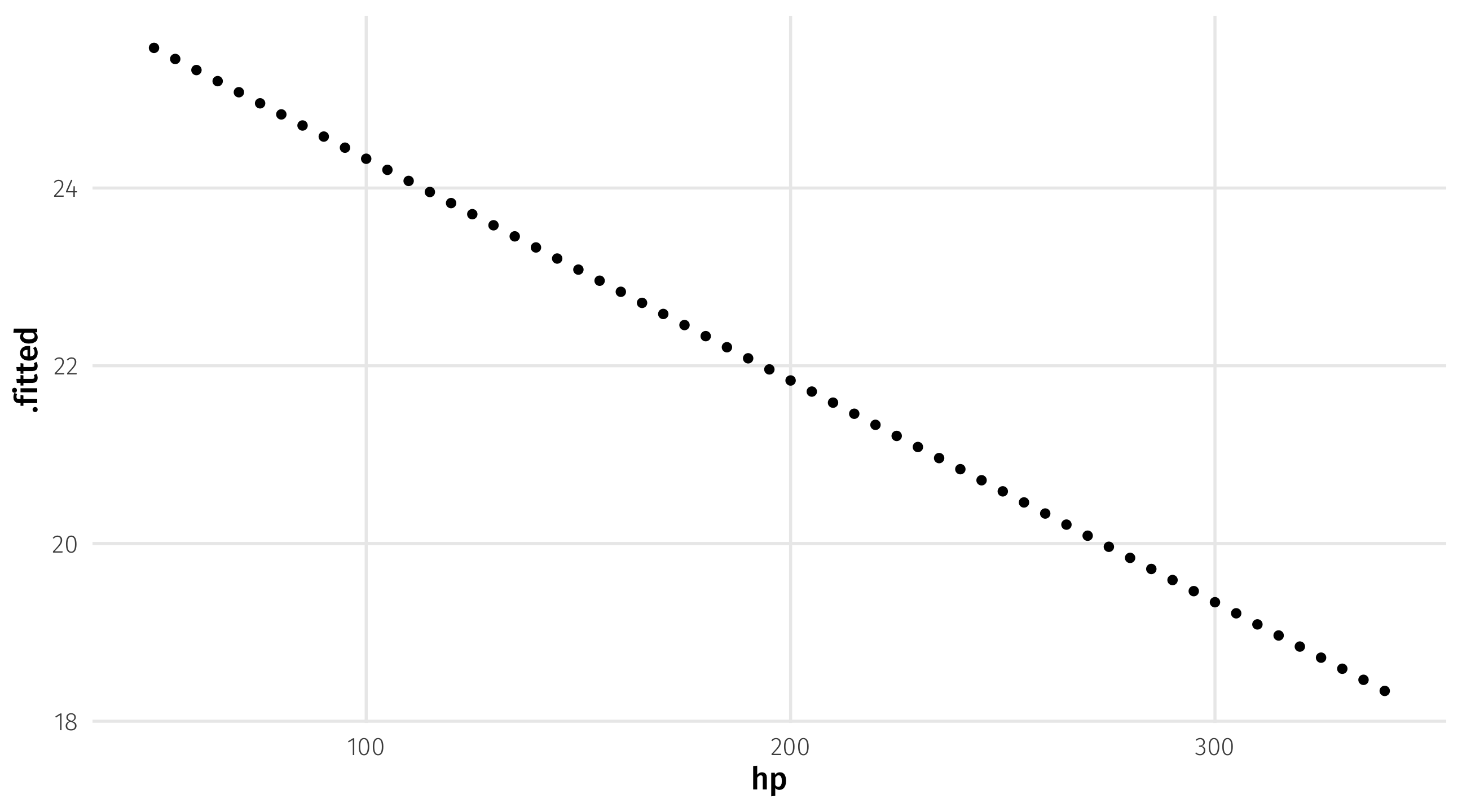
Visualizing predictions
We could then store our estimate, and use it for plotting
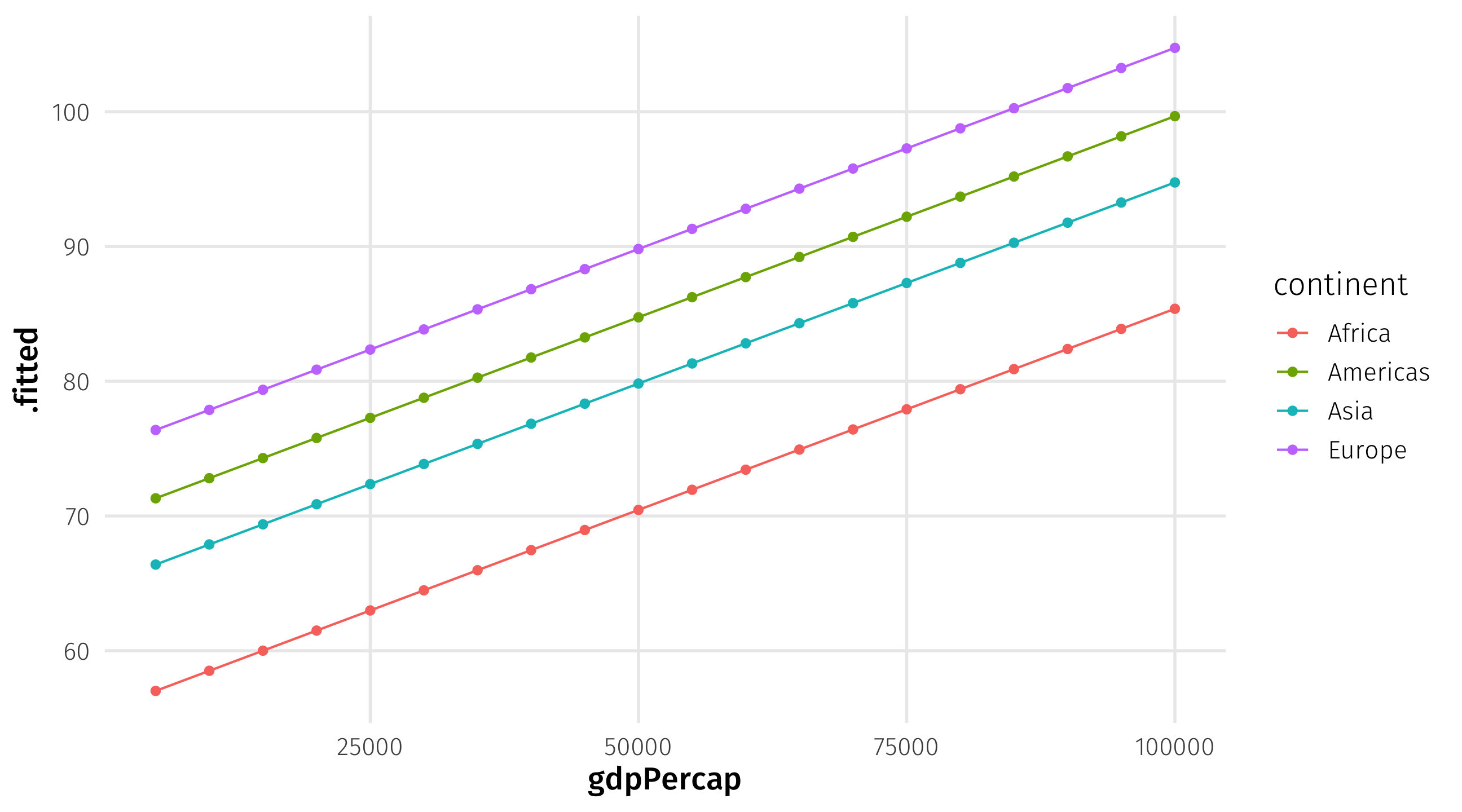
Predicting health
We can then save our predictions as an object, and plot them:
Your turn: 🤴 Colonial fire sale 🤴
- During the 1600s and 1700s the Spanish Crown would sell colonial governorships to raise money
- Governorships were valuable because you could tax / exploit the local population

Charles II. His wife: “The Catholic King is so ugly as to cause fear and he looks ill.”
Prediction accuracy
- The question with prediction is always: how accurate were we?
- If our model is predicting the outcome accurately that might be:
- a good sign that we are modeling the process that generates the outcome well
- useful for forcasting the future, or situations we don’t know about
Is this really a prediction?
Our estimate of Jamaica is not really prediction, since we used that observation to fit our model
This is an in-sample prediction \(\rightarrow\) seeing how well our model does at predicting the data that we used to generate it
“True” prediction is out-of-sample \(\rightarrow\) using a model to generate predictions about something that hasn’t happened yet
