82.4% of households in our sample have a TV in their home. This is an estimate based on one sample. How uncertain should we feel about this estimate given our sample size and variability?
We can bootstrap 1,000 samples with replacement of the same size as ours:
set.seed(1990)# how uncertain should we be?boots = wealth |>rep_sample_n(size =1560, reps =1000, replace =TRUE) |>summarise(r1_avg =mean(r1, na.rm =TRUE))
We can then look at the distribution of likely averages:
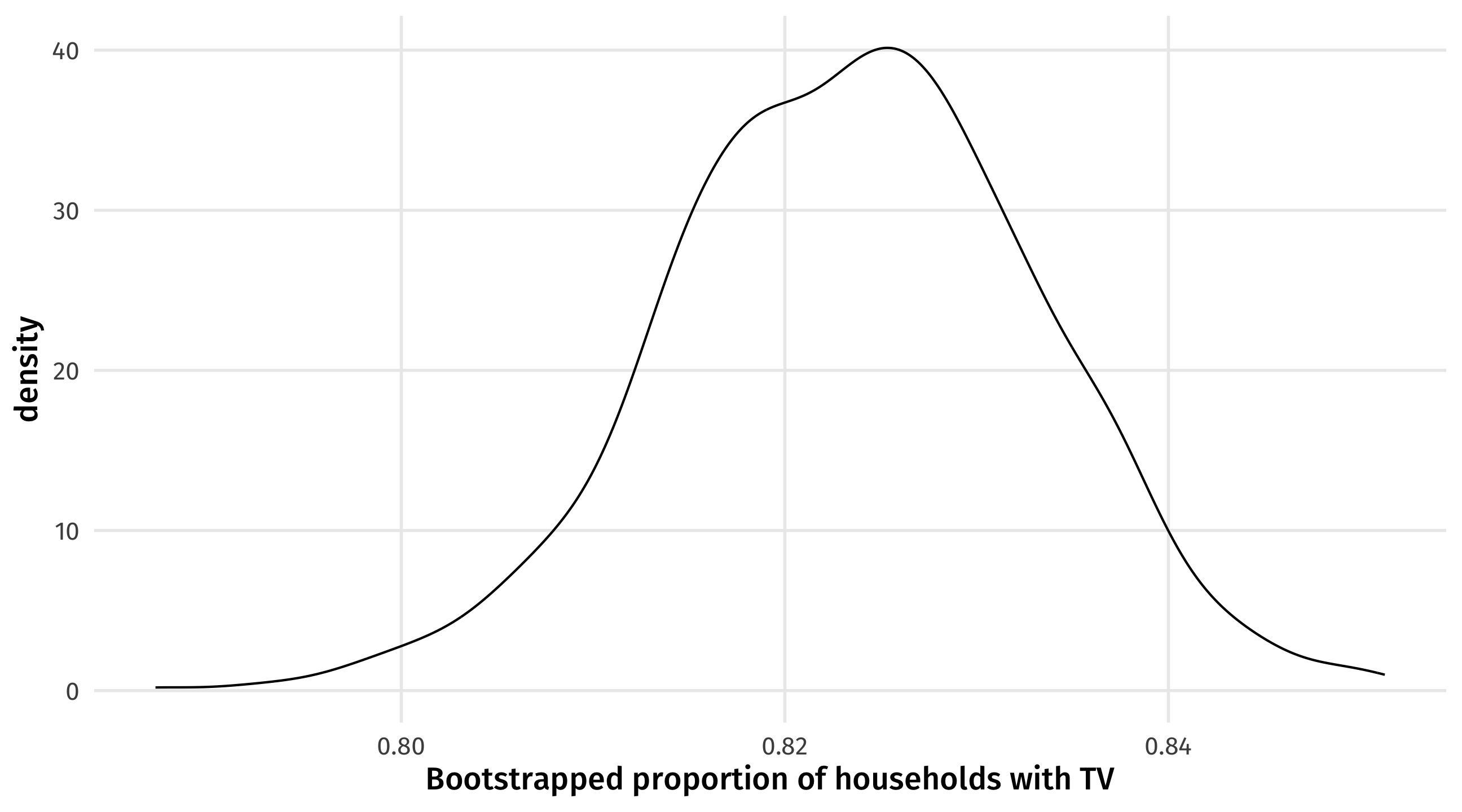
ggplot(boots, aes(x = r1_avg)) +geom_density() +labs(x ="Bootstrapped proportion of households with TV")
We can quantify uncertainty using the standard error:
## standard error?boots |>summarise(r1_avg_avg =mean(r1_avg, na.rm =TRUE),r1_se =sd(r1_avg, na.rm =TRUE))
r1_avg_avg
r1_se
0.824
0.00966
So our best guess is \(Estimate \pm 2 \times StandardError\) = \(.82 + 2 \times .01 = .84, .82 - 2 \times .01 = .80\)
Our best guess for percent of households in Honduras with a TV is between 80% and 84%.
We can also look at the 95% CI:
## confidence interval?boots %>%summarise(low =quantile(r1_avg, .025),mean =mean(r1_avg), high =quantile(r1_avg, .975))
low
mean
high
0.804
0.824
0.842
When we do regression with lm, R returns two measures of uncertainty: (1) the standard error, and (2) whether the 95% confidence interval excludes zero (ie., statistical significance)
mod =lm(mpg ~ wt, data = mtcars)huxreg(mod, statistics ="nobs")
(1)
(Intercept)
37.285 ***
(1.878)
wt
-5.344 ***
(0.559)
nobs
32
*** p < 0.001; ** p < 0.01; * p < 0.05.
The standard error is the number in parentheses below each coefficient. The standard error for wt is (.56).
The stars tell you whether a result is statistically significant or not, and what size of confidence interval excludes zero. The estimate for wt is statistically significant, and the 99.9% (100 - .001) confidence interval.